yahooニュース 産経新聞、首相「腹を割って意見交換」 7、8日に訪韓し尹大統領と会談 岸田文雄首相は1日(日本時間2日)、7~8日の日程で韓国を訪問し、尹錫悦(ユン・ソンニョル)大統領と会談する方向で調整(ちょうせい)していると明らかにした。訪問先(ほうもんさき)のガーナで記者団の取材に答えた。首相は尹氏が3月に来日(らいにち)した際(さい)、首脳同士が相互(そうご)に訪問する「シャトル外交」の再開(さいかい)で合意(ごうい)しており、その第1弾(いちだん)となる。 続いて、日本政府は4月28日に韓国を輸出手続き簡略化などの優遇措置の対象国となる「グループA(旧ホワイト国)」に再指定(さいしてい)する方針を発表したが、首相の訪韓(ほうかん)で成果(せいか)を示(しめ)せるかが焦点(しょうてん)になると書いていました。 日韓関係が改善されているようでうれしい記事でした。
Random Forest
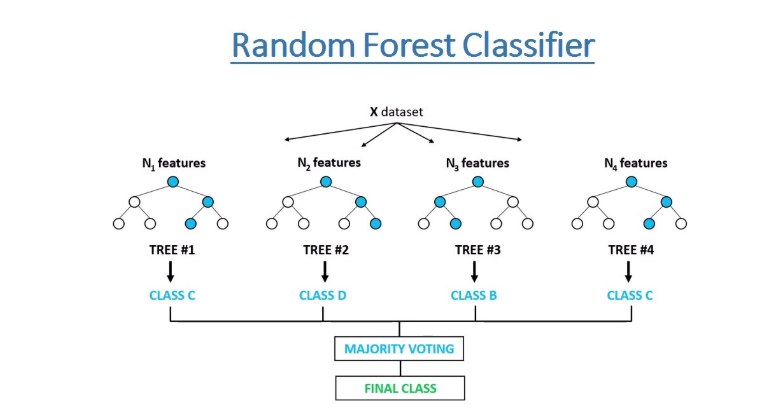
Random Forest는 weak Learner로 Decision Tree를 이용하는 일종의 bagging Algorithm이다. (배깅 학습기라는 뜻은 아니다) Machine Learning 분야에서 Support Vector Machine과 같이 가장 많이 사용하는 분류모형 중 하나이다. Random Forest Class는 다음 특징을 가진다.
- Keyword Argument의 대부분은 DecisionTreeClassifier와 같다. Random Forest에서 Tree의 수가 많아질수록 예측에 유리하지만 시간이 많이 걸리고, 한계적인 이득은 체감한다.
- Random Forest의 Base Model로는 보통 Deep Tree를 많이 사용한다.
- Shallow tree는 상대적으로 분산이 작지만 상당한 편의를 발생시킨다.
- 반면 Deep Tree는 분산이 큰 반면 편의가 작으므로 여러 결과의 평균을 예측에 사용하면 분산을 줄이는 효과가 있다.
- Random Features
- Random Forest는 훈련 과정에서 무작위로 추출한 Feature Set만을 사용한다. 이는 모형들 사이의 Correlation을 감소시킨다
- Missing Value와 관련된 문제를 효과적으로 완화시킨다.
오늘은 Random Forest와 Decision Tree의 기본 구조를 알고 있다고 가정하고 Keyword Argument 중 중요한 것들을 중심으로 소개하고자 한다.
class_weight
- {class_label:weight} 형식의 클래스와 연결된 가중치이다. 만약 주어지지 않는다면, 모든 Class는 하나의 가중치로 되어 있다. 다중 출력 문제의 경우 dict 목록을 y 열과 같은 순서로 제공할 수 있다.
- 다중 출력(다중 레이블 포함)의 경우 자체 dict의 모든 열의 각 클래스에 대해 가중치를 정의해야 한다. 예를 들어 4개 클래스의 다중 레이블 분류 가중치는 [{1:1}, {2:5}, {3:1}, {4:1} 대신 [{0:1, 1:1}, {0:1, 1:5}, {0:1, 1:1}, {0:1}]이어야 한다.
- "balanced" 모드는 y 값을 사용하여 입력 데이터의 클래스 빈도수에 반비례하는 가중치를 n_sample / (n_classes * np.bincount(y))로 자동 조정한다. 반면 "balanced_subsample" 모드는 "balanced" 모드와 동일하지만 가중치는 성장한 모든 트리에 대한 Bootstrap sample을 기반으로 계산된다.
- 다중 출력의 경우 y의 각 열의 가중치가 곱해지는데, sample_weight가 지정된 경우 이러한 가중치는 sample_weight(적합 방법을 통해 전달됨)로 곱해진다.
ccp_alpha
최소 비용-복잡도 가지치기에 사용되는 복잡성 매개 변수이다. ccp_alpha보다 비용 복잡도가 가장 큰 하위 트리가 선택된다. 기본적으로 가지치기는 수행되지 않는다. 여기서 비용-복잡도 문제는 Information Gain 계산 문제이며, 정보이득이 크면 Decision Tree는 분기를 진행하는데, ccp_alpha는 이러한 분기 문제에서 규제를 넣음으로써 과적합을 예방할 수 있다.
정보이득과 Impurity, Entropy에 관한 설명은 본문 위쪽에 작성자가 작성한 Random Forest에 대한 설명을 참조하길 바란다.
criterion
가지 분기의 기준 측정하는 Argument이다. 지원되는 criterion은 Gini Impurity에 대한 "gini"와 섀넌 Information Gain에 대한 "log_loss" 및 "entropy"이다.
댓글
댓글 쓰기