yahooニュース 産経新聞、首相「腹を割って意見交換」 7、8日に訪韓し尹大統領と会談 岸田文雄首相は1日(日本時間2日)、7~8日の日程で韓国を訪問し、尹錫悦(ユン・ソンニョル)大統領と会談する方向で調整(ちょうせい)していると明らかにした。訪問先(ほうもんさき)のガーナで記者団の取材に答えた。首相は尹氏が3月に来日(らいにち)した際(さい)、首脳同士が相互(そうご)に訪問する「シャトル外交」の再開(さいかい)で合意(ごうい)しており、その第1弾(いちだん)となる。 続いて、日本政府は4月28日に韓国を輸出手続き簡略化などの優遇措置の対象国となる「グループA(旧ホワイト国)」に再指定(さいしてい)する方針を発表したが、首相の訪韓(ほうかん)で成果(せいか)を示(しめ)せるかが焦点(しょうてん)になると書いていました。 日韓関係が改善されているようでうれしい記事でした。
금융시장의 미시적 구조

금융시장에는 다양한 시장 참여자들이 존재한다. 당장 한국의 주식 시장만 보더라도, 소위 개미로 불리우는 개인 투자자와 국민연금과 같은 기관, 고객들의 자산을 맡아 관리하는 자산운용사들과 수많은 대형 투자자들 등이 존재한다.
매수 매도 호가창을 보면, 그들이 지금까지 행한 거래기록와 bid ask information을 볼 수 있는데, 이 정보에는 각각의 시장 참여자들의 개인적인 전략이 숨어 있는 private information을 포함하고 있다.
Bid Ask tick을 통해 Daily Data로는 볼 수 없는 정보를 추출해낼 수 있다.

Bar
매수매도 주문와 장부를 통계학적으로 해석하기 위해서는 정규화된 형태로 저장해야 한다. 시계열 데이터를 통계적으로 해석할 수 있는 데이터로 만들기 위해서는 정상성을 띈 데이터로 변환을 해야 하는데, 많은 문헌에서 시간을 기준으로 한 Bar 보다 Volume과 Dollar Value를 기준으로 추출한 표본이 정규성과 정상성에서 더욱 강건한 경향을 보였다.
저자인 Prado 교수는 기존 문헌에서 많이 사용되는 표준 바와 더불어, Information driving bar 또한 소개하고 있다.
표준 바
Time Bar
시간 바는 고정된 시간 간격으로 정보를 표본 추출하여 생성한다. Python Library 혹은 KODEX 등에서 데이터를 구매하면 가장 기본적으로 구성된 정보의 형태이다. 저자인 Prado 교수는 다음과 같은 이유로 사용을 자제하는 것을 권장한다
- 시장은 정보를 일정한 시간 간격으로 처리하지 않는다
- 시간에 따라 추출된 시계열 자료는 종종 좋지 않는 통계적 성질을 보인다.
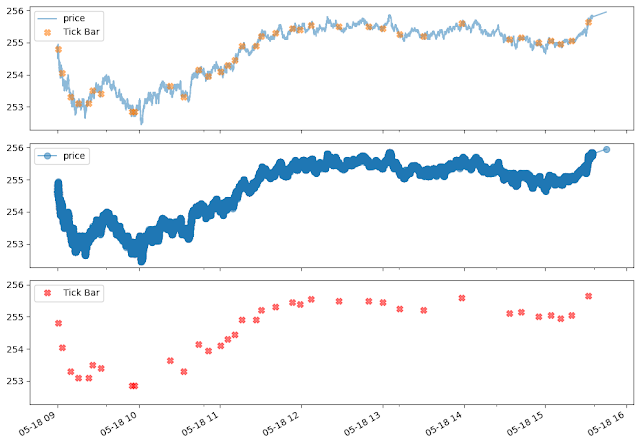
Tick Bar
틱 바의 기본적인 아이디어는 간단하다. 사전에 정해둔 거래 건수를 넘어갈 때마다 추출하는 것이다. 이렇게 하면 정보의 도착과 표본 추출을 동기화할 수 있다. 경험적으로는 600틱 정도가 좋은 듯 하다.
틱 바를 구성할 때에는 Outlier에 주의해야 한다. 많은 거래소에서 장 시작과 장 종료에 대량 장외가 거래를 수행한다. 이 시점에서 행해지는 거래는 하나의 틱이라도 정보량만 보면 수천개의 틱과 맞먹을 수 있다.
import FinancialMachinieLearning as fml
threshold = 600
tick_df = fml.bar_sampling(df, 'price', threshold, tick = True)
fml.plot_sample_data(xdf, xtdf, 'Tick Bar', alpha = 0.5, markersize = 7)

Volume Bar
틱 바의 문제점 중 하나는 주문의 파편성으로 틱의 수가 임의적이라는 이야기이다. (즉, 일종의 Hyper Parameter로, 사용자가 어떻게 지정하느냐에 따라서 time lag의 차이가 발생한다) 또한, 거래소의 가격 매치 엔진 프로토콜은 운영의 편의성을 위해 하나의 주문 체결을 다수의 인위적 Partial Order로 분리할 수 있다. 거래량 바는 이러한 문제를 미리 정의된 단위의 증권 거래가 일어날 때마다 표본 추출해 해결한다.
거래량에 기반을 둔 return data의 표본이 틱 바에 의한 표본추출된 데이터보다 훨씬 더 나은 통계적 성질 (IID 가우시안 분포의 가정을 더 잘 따른다)을 가진다는 것이 밝혀졌다.(Clark, 1973)
Financial Machine Learning Library에서는 다음과 같이 몇 개의 명령어만으로 거래량기준 표준 바를 추출할 수 있다.
import FinancialMachinieLearning as fml
volume_threshold = 10000
v_bar_df = fml.bar_sampling(df, 'v', volume_threshold, tick = False)
xdf, xtdf = fml.select_sample_data(df, v_bar_df, 'price', xDate)
fml.plot_sample_data(xdf, xtdf, 'Volume Bar', alpha = 0.5, markersize = 7)


Dollar Bar
달러 바는 사전에 정해 둔 시장 가치가 거래될 때마다 관측값을 표본 추출하는 것이다. 여기서 달러는 각 나라 화폐 단위에 따라 엔, 원, 혹은 파운드, 유로 등이 될 수 있다. (즉, 굳이 달러가 아니어도 된다) 거래 가치를 기준으로 표본을 추출하면 가장 큰 장점으로 큰 가격 변동에 영향을 많이 받지 않는다는 장점이 있다. 또한, 수집된 데이터 상에서 발생한 액면분할 등의 기업의 재무활동에 강건한 경향을 보인다는 장점도 있다.

Financial Machine Learning Library에서는 아래와 같이 손쉽게 달러 바 표본을 추출할 수 있다
import FinancialMachinieLearning as fml
dollar_threshold = 3000000
dv_bar_df = fml.bar_sampling(df, 'dv', dollar_threshold, tick = False)
xdf, xtdf = fml.select_sample_data(df, dv_bar_df, 'price', xDate)
fml.plot_sample_data(xdf, xtdf, 'dollar bar', alpha=0.5, markersize=7)


댓글
댓글 쓰기